We’re trying to figure out how to create a “flow” that will allow us to have:
1 configuration that’s acting as a “master trigger” to be queued manually.
multiple configurations that are triggered when the master configuration build completes running.
a “final” configuration that should only trigger when all other configurations have finished successfully.
=============
I already implemented similar logic in the past (see here)
The challenge now is: have the ability to run multiple such “flows” simultaneously while preserving some context between the running builds - so that If we triggered multiple such “flows” then the configurations running for each of these flows will output their artifacts to different output folders based on the unique context provided to them by the master trigger configuration.
I know how to pass a unique context, say the build number - as a variable in the trigger to the triggered configurations.
but I don’t yet know if/how it is possible to trigger the last “final” configuration only after multiple configurations with the same context “XYZ” finished running - I need some way to count this.
counting this in a global variable doesn’t work because I can’t tell which context is being counted…
keeping multiple global/project scope counters for multiple contexts - is also a problem because I can’t dynamically set which variable (counter) to update in the persist event handlers or in the update variable action.
Can you suggest a clean way to achieve this?
Thanks!
Does each of the “flows” contain a distinct set configurations? If so, maybe you use a separate count variable for each flow and use a single initial configuration to trigger all the flows.
If, as I suspect, each of the “flows” contains all or some of the same configurations, then that is more difficult.
You could still have multiple counter variables and persist all of them at the end of each configuration. Use actions at the end of the last stage to increment only one of them based on some conditional if/then logic. e.g. (pseudo code)
If triggeringConfig = "MasterConfig1" then SetVariable(increment count1);
If triggeringConfig = "MasterConfig2" then SetVariable(increment count2).
Alternatively, you could use a single global variable, but set it to be an array of counters, one for each triggering context, e.g. “0,0,0”. Each configuration would increment one value depending on the triggering context. There’s not really a simple way to set array values in Continua, but this may be possible by calling a script or executable. The trigger condition would then check the relevant item in the array, e.g. $Utils.GetString(%ArrayOfCounters%).Split(",").Item(2)$ Equals "3". Obviously this is a lot more complex than using multiple counter variables.
Thank you for the detailed reply Dave!
As you suspected, each “flow” contains all or some of the same configurations.
This was very helpful!
The only thing is:
When incrementing a project scope variable through stage logic - there’s a race condition:
all configurations (triggered simultaneously by the master configuration) are holding the same value for the “global” (project scope) variable
so they all increment it to the same value and the final count is wrong.
The solution we found for this - is to increase the counter in the persist event handlers with a condition that checks what is the context, so the event handler to increase counter X will only fire if the context is the one relevant for counter X.
So, we have a working solution after all!
Thanks again Dave! Cheers!
One solution for this is to run the logic in a small final stage which is set to acquire a single shared resource lock.
Nice - this will work well and doesn’t require extra shared resources to maintain. The variable persistence is locked so no two builds can update the same variable concurrently, so this great for incrementing counters.
Yep, we’re happy with this solution so far!
Alas, we’ve stumbled upon another challenge here - so we have a follow-up question for you, if you will:
The master configuration gets its context by means of acquiring a read lock (label) from a server scope shared resource (quota list).
Since the master configuration is only used for triggering the other configurations -
it finishes its run quickly, and releases the lock quickly as well.
This creates a scenario where someone else could trigger the master config - and it may acquire the same label it released a few seconds ago - while the other configurations that were triggered from the first run - are still running their full duration with the context generated from the that label.
We need this lock to be held by the master configuration until all other configurations that were triggered by it - have completed their own runs as well.
We tried to:
Add a last stage (empty…) to the master configuration.
Disable auto-promote for the preceding stage.
Check “Hold resource lock if a build stage waits for manual promotion” on the configuration condition that acquires the lock for the master configuration.
Set-up a condition that will promote to the next step - effectively causing it to release its lock only after everything else finished running.
However - we can’t seem to find a way to trigger stage promotion using conditions:
Because If the stage promotion conditions evaluate expressions using global/project scope variables - then these variables are already pre-set when the stage promote conditions are evaluated (Right?).
And persisting global/project scope variables from other configurations will not change its value in the scope of the already triggered master configuration that is waiting for manual/conditional promotion.
Is there a way to control stage promotion conditions from outside of the the master configuration scope?
Stage promotion conditions are only checked once when the stage completes, so you can’t really use them for this purpose. We are working on a REST API for v2 which will include an endpoint for triggering stage promotion. For now, however, this little feature that I’m working on should help with your scenario:
If I understand correctly this means that if a stage has auto promote disabled, and the stage already completed. and promotion conditions were not satisfied once it completed - then the only way to promote it is manually?
Sounds good!! We can’t wait to try out v2!
Nice! Actually we already sort-of implemented this feature ourselves:
We pass the context variable from the triggering config, and use an acquire expression with the context to acquire the same label on the triggered configs, alas this doesn’t resolve our issue:
if we trigger config_master which in turn triggers configs 1,2,3 simultaneously:
if config1,2,3 are to take the same lock as config_master this will force them to run sequentially, but we want them to all run simultaneously to save a lot of time.
if we use a quota list label with a quota of 4 (for master,1,2,3) then we still have a race condition:
config_master finishes its own run in 1 second and releases the lock immediately, freeing 1 from the quota, which another config_master run could take (bad).
also, say config1,2,3 were triggered from config_master - these are doing different tasks so some will finish running before others, each config completion frees 1 quota thus allowing other config_master runs to take from this label quota as well.
Is there any way to change a global/project scope variable (or a different type of objects)
so that it could be evaluated and detected inside a build that is already running? (inside a while loop for example).
We have already been looking into this problem, one possibility would be to use a shared resource label with a quota of say 3 to match the number of triggered configs. The config_master would need to acquire a write lock on this shared resource, config1, 2 and 3 would acquire a read lock. The config_master would not be able to acquire a write lock while config1, 2 or 3 have a read lock.
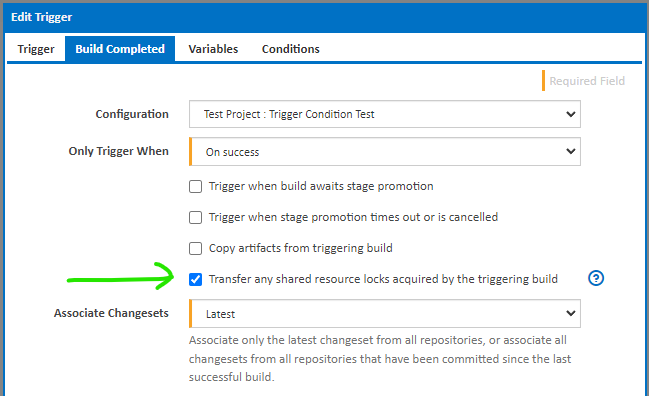
Alternatively, we could set up a single shared resource label with an option to allow build completed triggers to exceed quotas when transferring locks.
The idea of transferring the locks via the trigger is to prevent race conditions between one build completing and the other starting.
Maybe one day, but that’s a bit more complex than it may appear - particularly as it will require concurrency locking between the agent and the server.
That’s a game changer!
We weren’t aware of this behavior, it resolves our issue almost completely
Almost - because the only thing that’s still bothering us now is the race condition you mentioned:
Fortunately - you also mentioned this is a feature that you are working on, so we hope to see this issue resolved when you release it!